详解正则化
159人参与 • 2024-08-02 • 正则表达式
(一)正则化目的
防止过拟合现象,通过降低模型在训练集上的精度来提高其泛化能力,从而增加正则项
常见的降低过拟合方法
■增加数据集的数据个数。数据量太小时,非常容易过拟合,因为
小数据集很容易精确拟合。
■找到模型优化时的平衡点,比如,选择迭代次数,或者选择相对简单的模型。
■正则化。
(二)正则化参数
机器学习中的正则化通过引入模型参数λ(lambda)来实现。
(2.1)常见的损失函数
加入了正则化参数之后线性回归均方误差损失函数公式
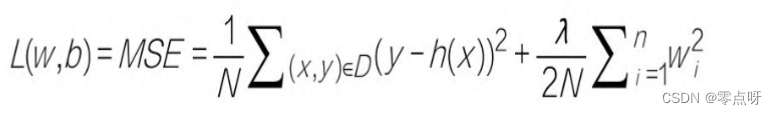
加入了正则化参数之后的逻辑回归均方误差损失函数公式
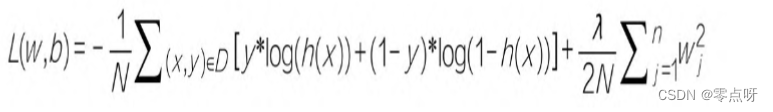
以上公式,一个由两项内容组成的函数:一个是损失项,用于衡量模型与数据的拟合度;
另一个是正则化项,用于调解模型的复杂度。
l1正则化
根据权重的绝对值的总和来惩罚权重。l1正则化有助于使不相关或几乎不相关的特征的权重正好为0,从而将这些特征从模型中移除。
l2正则化
根据权重的平方和来惩罚权重。l2 正则化有助于使离群值(具有较大正值或较小负值)的权重接近于0,但又不会正好为
0。在线性模型中,l2 正则化比较常用,而且在任何情况下都能够起到增强泛化能力的目的。
用l1正则化的回归又叫lasso regression(套索回归),应用l2正则化的回归又叫ridge regression(岭回归)。
赞 (0)
打赏
 微信扫一扫
微信扫一扫
微信扫一扫
您想发表意见!!点此发布评论





发表评论