Rust集合中向量和散列值映射表Hash Map与字符串
402人参与 • 2024-08-02 • rust
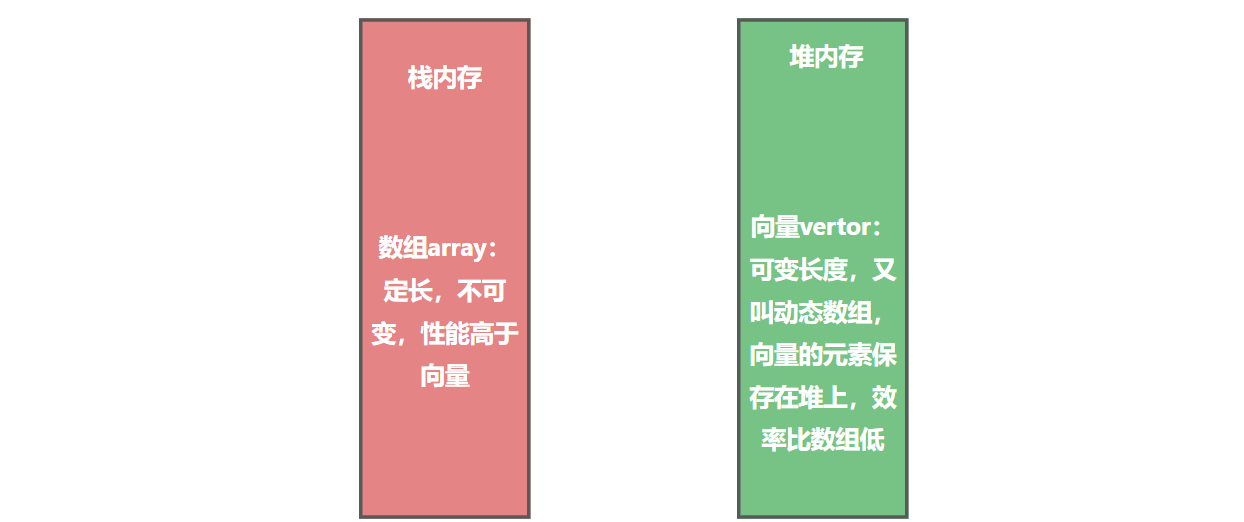
数组和向量
rust中数组分为两类:长度固定的array,动态数组vector。array的效率比vector高,array存栈上,vector存堆上。
数组特点:固定长度,不可变,存在栈上,处理数据效率比向量高。类型定义是[t;n]
向量特点:也叫动态数组,长度可变,可以动态修改元素,存在堆上,效率没有数组高。类型定义是:vec<t>
vec是一种动态的可变数组,可以在运行时增长或者缩短数组的长度。其签名形式vec<t>,t表示任意类型。vec<t>叫做t类型的向量。向量的元素保存在堆上,这也是它可以动态增长或者缩短长度的原因。向量中的每个元素都分配有唯一的索引值,同数组一样,索引从0开始计数。
数组创建
// [类型;长度]
let a: [i32; 5] = [1, 2, 3, 4, 5];数组切片:
let a :[i32;5] = [1,2,3,4,5];
let a :&[i32] = &a[1..3] 数组切片是对数组的引用,所以效率也比较高。注意数组切片类型和数组类型不一样。数组类型是[t,n],切片类型是[t],因为切片是个运行期的数据结构,其长度在编译阶段不知道。
注意,[u8;3]和[u8;4]是不同类型,数组长度也是类型的一部分。
向量创建
let vector: vec<i32> = vec::new(); // 创建类型为 i32 的空向量
let vector = vec![1, 2, 4, 8]; // 通过数组创建向量向量追加元素:
fn main() {
let mut vector = vec![1, 2, 4, 8];
vector.push(16);
vector.push(32);
vector.push(64);
println!("{:?}", vector);
}运行结果:
[1, 2, 4, 8, 16, 32, 64]append 方法用于将一个向量拼接到另一个向量的尾部:
fn main() {
let mut v1: vec<i32> = vec![1, 2, 4, 8];
let mut v2: vec<i32> = vec![16, 32, 64];
v1.append(&mut v2);
println!("{:?}", v1);
}运行结果:
[1, 2, 4, 8, 16, 32, 64]修改元素:
直接使用“变量名称[索引] = 要修改的值”即可重新为元素赋值。下面的代码是将向量的第4个元素(索引值3的元素)的值修改为1。修改元素需要将向量使用mut关键字修饰
let mut vec_push = vec![0; 5];
vec_push[3] = 1;删除元素:pop | remove
通过pop方法弹出队尾元素。调用pop方法会返回一个option枚举类型。如果数组不为空,则会返回some(v),v是弹出的值。如果向量为空,则会返回none:
let mut vec_pop = vec![1];
let pop = vec_pop.pop();通过remove方法删除元素,需要传入将要删除元素的索引,并且返回删除的元素。这个操作会引发向量元素的移位,被删除元素的后面元素都会相应的左移一位。如果传入的索引大于向量的长度,则会产生程序错误:
let mut vec_remove = vec!['w', 'o', 'r', 'l', 'd'];
let remove_element = vec_remove.remove(3);
// 索引越界,会发生错误
// let remove_element = vec_remove.remove(5);访问元素:索引访问或者get
使用“向量名称[索引]”的方式访问指定元素,类似于修改元素的访问。如果传入的索引大于向量的长度,则会产生程序错误,常称作数组越界:
let vec_find = vec![1, 2, 3];
vec_find[0] 使用get方法访问元素,传入的参数同样是索引,但是其犯规之是option枚举类型,如果索引越界,不会产生错误,则会返回none:
let vec_get = vec![1, 2, 3];
vec_get.get(0)遍历向量
fn main() {
let v = vec![100, 32, 57];
for i in &v {
println!("{}", i);
}
}运行结果:
100
32
57如果遍历过程中需要更改变量的值:
fn main() {
let mut v = vec![100, 32, 57];
for i in &mut v {
*i += 50;
}
}向量容量增长策略
向量的容量(capacity)是指为存储元素所分配的空间。向量的长度(length)如果大于其当前的容量,则会发生重新分配空间的操作,这个过程比较耗时。假设当前数组的容量为5,如果向量内的元素小于等于5个,则其容量不会增加,如果元素超过5个,则向量的容量就会重新分配,在原有的基础上乘以2(目前2是向量的增长因子),最后容量会变成10。因此尽可能的在初始化时为其指定合适的容量。
映射表
映射表(map)在其他语言中广泛存在。其中应用最普遍的就是键值散列映射表(hash map)。
新建一个散列值映射表:
use std::collections::hashmap;
fn main() {
let mut map = hashmap::new();
map.insert("color", "red");
map.insert("size", "10 m^2");
println!("{}", map.get("color").unwrap());
}注意:这里没有声明散列表的泛型,是因为 rust 的自动判断类型机制。
运行结果:
redinsert 方法和 get 方法是映射表最常用的两个方法。
映射表支持迭代器:
use std::collections::hashmap;
fn main() {
let mut map = hashmap::new();
map.insert("color", "red");
map.insert("size", "10 m^2");
for p in map.iter() {
println!("{:?}", p);
}
}运行结果:
("color", "red")
("size", "10 m^2")迭代元素是表示键值对的元组。
rust 的映射表是十分方便的数据结构,当使用 insert 方法添加新的键值对的时候,如果已经存在相同的键,会直接覆盖对应的值。如果你想"安全地插入",就是在确认当前不存在某个键时才执行的插入动作,可以这样:
map.entry("color").or_insert("red");这句话的意思是如果没有键为 "color" 的键值对就添加它并设定值为 "red",否则将跳过。
在已经确定有某个键的情况下如果想直接修改对应的值,有更快的办法:
use std::collections::hashmap;
fn main() {
let mut map = hashmap::new();
map.insert(1, "a");
if let some(x) = map.get_mut(&1) {
*x = "b";
}
}
字符串
字符串类(string)到本章为止已经使用了很多,所以有很多的方法已经被读者熟知。本章主要介绍字符串的方法和 utf-8 性质。
新建字符串:
let string = string::new();基础类型转换成字符串:
let one = 1.to_string(); // 整数到字符串
let float = 1.3.to_string(); // 浮点数到字符串
let slice = "slice".to_string(); // 字符串切片到字符串包含 utf-8 字符的字符串:
let hello = string::from("السلام عليكم");
let hello = string::from("dobrý den");
let hello = string::from("hello");
let hello = string::from("שָׁלוֹם");
let hello = string::from("नमस्ते");
let hello = string::from("こんにちは");
let hello = string::from("안녕하세요");
let hello = string::from("你好");
let hello = string::from("olá");
let hello = string::from("здравствуйте");
let hello = string::from("hola");字符串追加:
let mut s = string::from("run");
s.push_str("oob"); // 追加字符串切片
s.push('!'); // 追加字符用 + 号拼接字符串:
let s1 = string::from("hello, ");
let s2 = string::from("world!");
let s3 = s1 + &s2;这个语法也可以包含字符串切片:
let s1 = string::from("tic");
let s2 = string::from("tac");
let s3 = string::from("toe");
let s = s1 + "-" + &s2 + "-" + &s3;使用 format! 宏:
let s1 = string::from("tic");
let s2 = string::from("tac");
let s3 = string::from("toe");
let s = format!("{}-{}-{}", s1, s2, s3);字符串长度:
let s = "hello";
let len = s.len();这里 len 的值是 5。
let s = "你好";
let len = s.len();这里 len 的值是 6。因为中文是 utf-8 编码的,每个字符长 3 字节,所以长度为6。但是 rust 中支持 utf-8 字符对象,所以如果想统计字符数量可以先取字符串为字符集合:
let s = "hello你好";
let len = s.chars().count();这里 len 的值是 7,因为一共有 7 个字符。统计字符的速度比统计数据长度的速度慢得多。
遍历字符串:
fn main() {
let s = string::from("hello中文");
for c in s.chars() {
println!("{}", c);
}
}运行结果:
h
e
l
l
o
中
文从字符串中取单个字符:
fn main() {
let s = string::from("en中文");
let a = s.chars().nth(2);
println!("{:?}", a);
}运行结果:
some('中')注意:nth 函数是从迭代器中取出某值的方法,请不要在遍历中这样使用!因为 utf-8 每个字符的长度不一定相等!
如果想截取字符串字串:
fn main() {
let s = string::from("en中文");
let sub = &s[0..2];
println!("{}", sub);
}运行结果:en
但是请注意此用法有可能肢解一个 utf-8 字符!那样会报错:
fn main() {
let s = string::from("en中文");
let sub = &s[0..3];
println!("{}", sub);
}运行结果:
thread 'main' panicked at 'byte index 3 is not a char boundary; it is inside '中' (bytes 2..5) of `en中文`', src\libcore\str\mod.rs:2069:5
note: run with `rust_backtrace=1` environment variable to display a backtrace.
赞 (0)
您想发表意见!!点此发布评论



发表评论